

python爬虫常见面试题(二)
发布于2019-07-13 11:59 阅读(2592) 评论(0) 点赞(26) 收藏(91)
前言
之所以在这里写下python爬虫常见面试题及解答,一是用作笔记,方便日后回忆;二是给自己一个和大家交流的机会,互相学习、进步,希望不正之处大家能给予指正;三是我也是互联网寒潮下岗的那批人之一,为了找工作而做准备。
一、题目部分
1、scrapy框架专题部分(很多面试都会涉及到这部分)
(1)请简要介绍下scrapy框架。
(2)为什么要使用scrapy框架?scrapy框架有哪些优点?
(3)scrapy框架有哪几个组件/模块?简单说一下工作流程。
(4)scrapy如何实现分布式抓取?
2、其他常见问题。
(1)爬虫使用多线程好?还是多进程好?为什么?
(2)http和https的区别?
(3)数据结构之堆,栈和队列的理解和实现。
二、解答部分
1、scrapy框架专题部分
(1)请简要介绍下scrapy框架。
scrapy 是一个快速(fast)、高层次(high-level)的基于 python 的 web 爬虫构架,用于抓取web站点并从页面中提取结构化的数据。scrapy 使用了 Twisted异步网络库来处理网络通讯。
(2)为什么要使用scrapy框架?scrapy框架有哪些优点?
- 它更容易构建大规模的抓取项目
- 它异步处理请求,速度非常快
- 它可以使用自动调节机制自动调整爬行速度
(3)scrapy框架有哪几个组件/模块?简单说一下工作流程。
Scrapy Engine: 这是引擎,负责Spiders、ItemPipeline、Downloader、Scheduler中间的通讯,信号、数据传递等等!(像不像人的身体?)
Scheduler(调度器): 它负责接受引擎发送过来的requests请求,并按照一定的方式进行整理排列,入队、并等待Scrapy Engine(引擎)来请求时,交给引擎。
Downloader(下载器):负责下载Scrapy Engine(引擎)发送的所有Requests请求,并将其获取到的Responses交还给Scrapy Engine(引擎),由引擎交给Spiders来处理,
Spiders:它负责处理所有Responses,从中分析提取数据,获取Item字段需要的数据,并将需要跟进的URL提交给引擎,再次进入Scheduler(调度器),
Item Pipeline:它负责处理Spiders中获取到的Item,并进行处理,比如去重,持久化存储(存数据库,写入文件,总之就是保存数据用的)
Downloader Middlewares(下载中间件):你可以当作是一个可以自定义扩展下载功能的组件
Spider Middlewares(Spider中间件):你可以理解为是一个可以自定扩展和操作引擎和Spiders中间‘通信‘的功能组件(比如进入Spiders的Responses;和从Spiders出去的Requests)
整体架构如下图:
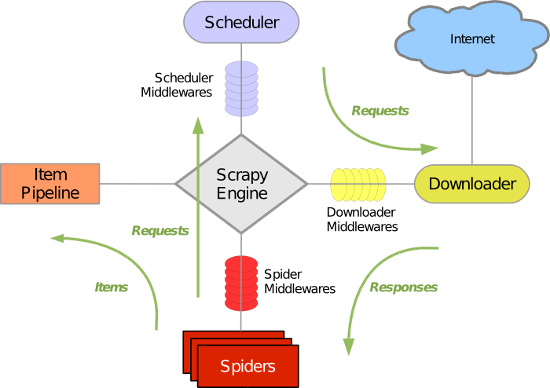
工作流程:
数据在整个Scrapy的流向:
程序运行的时候,
引擎:Hi!Spider, 你要处理哪一个网站?
Spiders:我要处理23wx.com
引擎:你把第一个需要的处理的URL给我吧。
Spiders:给你第一个URL是XXXXXXX.com
引擎:Hi!调度器,我这有request你帮我排序入队一下。
调度器:好的,正在处理你等一下。
引擎:Hi!调度器,把你处理好的request给我,
调度器:给你,这是我处理好的request
引擎:Hi!下载器,你按照下载中间件的设置帮我下载一下这个request
下载器:好的!给你,这是下载好的东西。(如果失败:不好意思,这个request下载失败,然后引擎告诉调度器,这个request下载失败了,你记录一下,我们待会儿再下载。)
引擎:Hi!Spiders,这是下载好的东西,并且已经按照Spider中间件处理过了,你处理一下(注意!这儿responses默认是交给def parse这个函数处理的)
Spiders:(处理完毕数据之后对于需要跟进的URL),Hi!引擎,这是我需要跟进的URL,将它的responses交给函数 def xxxx(self, responses)处理。还有这是我获取到的Item。
引擎:Hi !Item Pipeline 我这儿有个item你帮我处理一下!调度器!这是我需要的URL你帮我处理下。然后从第四步开始循环,直到获取到你需要的信息,
注意!只有当调度器中不存在任何request了,整个程序才会停止,(也就是说,对于下载失败的URL,Scrapy会重新下载。)
以上就是Scrapy整个流程了。
(4)scrapy如何实现分布式抓取?
可以借助scrapy_redis类库来实现。
在分布式爬取时,会有master机器和slave机器,其中,master为核心服务器,slave为具体的爬虫服务器。
我们在master服务器上搭建一个redis数据库,并将要抓取的url存放到redis数据库中,所有的slave爬虫服务器在抓取的时候从redis数据库中去链接,由于scrapy_redis自身的队列机制,slave获取的url不会相互冲突,然后抓取的结果最后都存储到数据库中。master的redis数据库中还会将抓取过的url的指纹存储起来,用来去重。相关代码在dupefilter.py文件中的request_seen()方法中可以找到。
去重问题:
dupefilter.py 里面的源码:
def request_seen(self, request):
fp = request_fingerprint(request)
added = self.server.sadd(self.key, fp)
return not added
去重是把 request 的 fingerprint 存在 redis 上,来实现的。
2、其他常见问题。
(1)爬虫使用多线程好?还是多进程好?为什么?
对于IO密集型代码(文件处理,网络爬虫),多线程能够有效提升效率(单线程下有IO操作会进行IO等待,会造成不必要的时间等待,而开启多线程后,A线程等待时,会自动切换到线程B,可以不浪费CPU的资源,从而提升程序执行效率)。
在实际的采集过程中,既考虑网速和相应的问题,也需要考虑自身机器硬件的情况,来设置多进程或者多线程。
(2)http和https的区别?
A. http是超文本传输协议,信息是明文传输,https则是具有安全性的ssl加密传输协议。
B. http适合于对传输速度、安全性要求不是很高,且需要快速开发的应用。如web应用,小的手机游戏等等。而https适用于任何场景。
(3)数据结构之堆,栈和队列的理解和实现。
栈(stacks):栈的特点是后进先出。只能通过访问一端来实现数据的储存和检索的线性数据结构。
队列(queue):队列的特点是先进先出。元素的增加只能在一端,元素的删除只能在另一端。增加的一端称为队尾,删除的一端称为队首。
栈:
1 stack = [1, 2, 3] 2 stack.append(4) 3 stack.append(5) 4 print(stack) 5 stack.pop() 6 stack.pop() 7 print(stack)
输出结果:
1 [1, 2, 3, 4, 5] 2 [1, 2, 3]
队列:
1 from collections import deque 2 3 queue = deque(['Eric', 'John', 'Michael']) 4 queue.append('Terry') 5 queue.append('Graham') 6 print(queue) 7 queue.popleft() 8 print(queue)
输出结果:
1 deque(['Eric', 'John', 'Michael', 'Terry', 'Graham']) 2 deque(['John', 'Michael', 'Terry', 'Graham'])
这里还会有一个常见的问题,栈溢出的常见情况及解决方案。
什么是栈溢出?
因为栈一般默认为1-2m,一旦出现死循环或者是大量的递归调用,在不断的压栈过程中,造成栈容量超过1m而导致溢出。
栈溢出的几种情况?
1、局部数组过大。当函数内部数组过大时,有可能导致堆栈溢出。
2、递归调用层次太多。递归函数在运行时会执行压栈操作,当压栈次数太多时,也会导致堆栈溢出。
解决方法:
1、用栈把递归转换成非递归。
2、增大栈空间。
所属网站分类: 技术文章 > 博客
作者:加班是一种习惯
链接:https://www.pythonheidong.com/blog/article/1223/dbc91e8fc90a2a20a4f1/
来源:python黑洞网
任何形式的转载都请注明出处,如有侵权 一经发现 必将追究其法律责任
昵称:
评论内容:(最多支持255个字符)
---无人问津也好,技不如人也罢,你都要试着安静下来,去做自己该做的事,而不是让内心的烦躁、焦虑,坏掉你本来就不多的热情和定力