本站消息


第二次力扣周赛:排名149 / 2046;在完赛边缘打转(总结了5点,实力还不够)
发布于2020-02-10 17:26 阅读(1206) 评论(0) 点赞(3) 收藏(2)
前言: 上午10:30 - 12:00 第二次力扣周赛,最后一题也写完了,但是没有通过。完成了 3 / 4 的题,排名 149 / 2046。
赛题:https://leetcode-cn.com/contest/weekly-contest-175
排名:https://leetcode-cn.com/contest/weekly-contest-175/ranking/
上周自己只做了一道题,排名是 890 / 1659 ,看来送分题都有一半的人不要,划水的人不少。上周打完比赛后,我大概练习了 6 道 LeetCode 来迎接今天的比赛。前两天我在忙一个仿真项目,用到基本的 python3 运算与 pygame 来操控窗体。
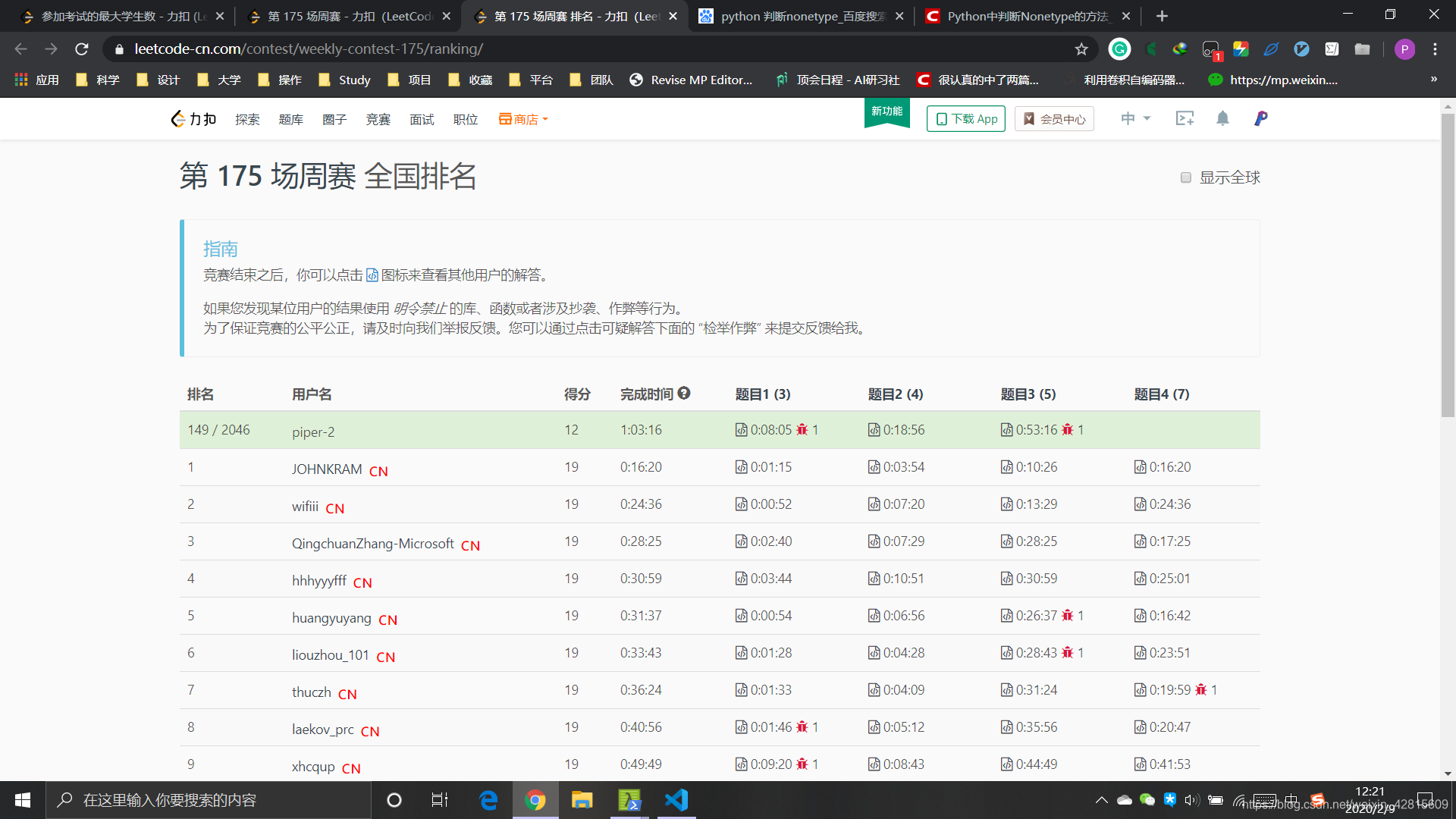
而本次排名为 149 / 2046 ,留给最后一题的时间大概为 35 分钟,在最后 10 分钟写好,但是未通过。
本次比赛大概五点心得:
- 题目难度不大,竞争对手水平两极分化;
- “马虎”(将在下面的复盘中讨论什么是“马虎”,以及如何避免);
- 起码的时间复杂度;
- 调试;
- 关掉 QQ 与微信!
1. 竞争环境
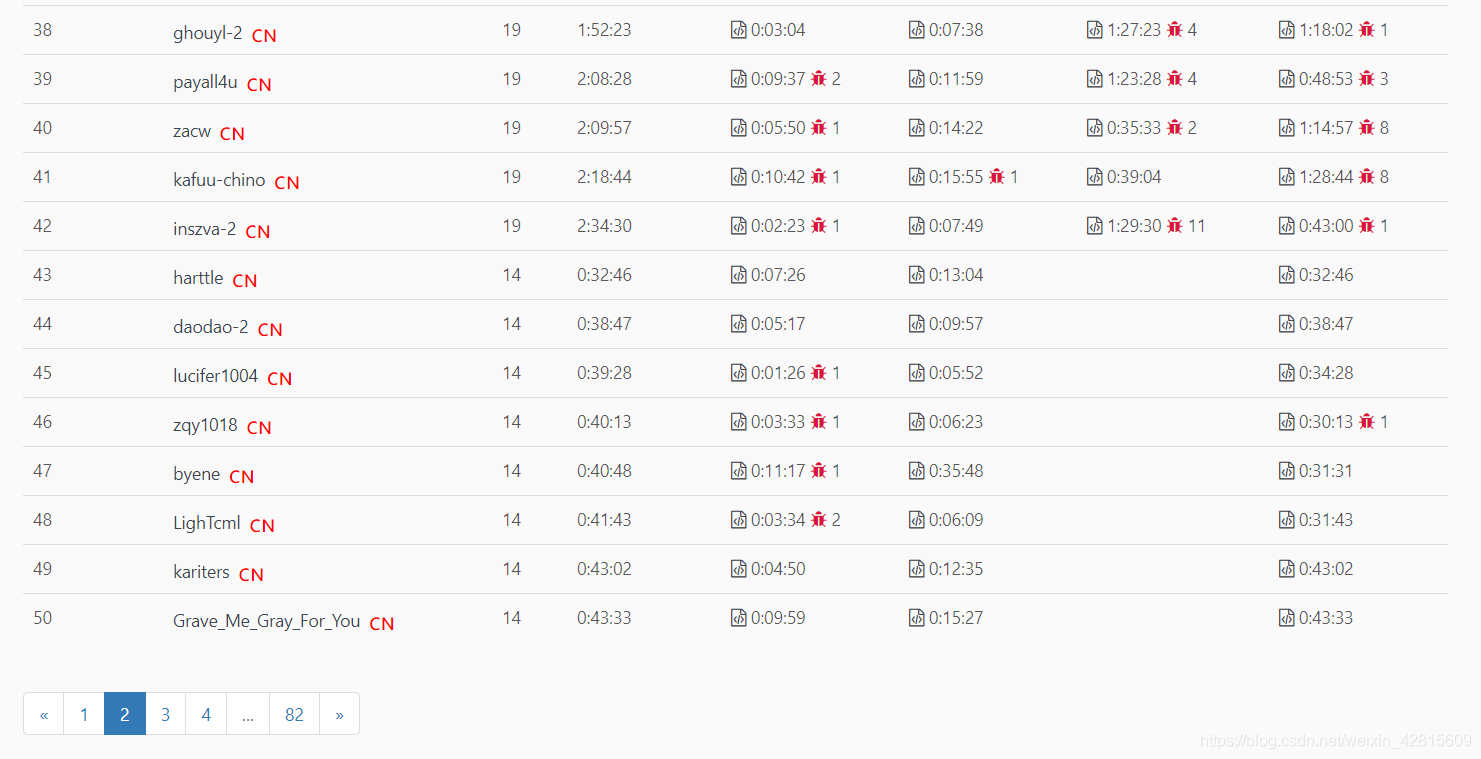
2046人报名参赛,只有42人完赛。竞争对手水平普遍一般。
我90分钟正好把题做完(最后一题已经写完,但运行报错未通过),而有高手16分钟就完赛,速度是我的6倍,几乎难以想象!
2. 复盘:“别马虎!”
百度百科:马虎,指漫不经心;不介意;疏忽;轻率。如:这人太马虎。也指勉强,将就的意思。
如果没有“马虎”,即使最后一题未通过,我的排名也会提升的20名左右。
5332. 检查整数及其两倍数是否存在
def checkIfExist(self, arr) -> bool:
def twice(a, b):
if a == b * 2:
return True
if a * 2 == b:
return True
return False
for i in range(len(arr)):
for j in range(len(arr) - i - 1):
if twice(arr[i], arr[j+i+1]):
# if twice(arr[i], arr[j]):
return True
return False
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
非常简单的一道题,我没有选择遍历 矩阵,而是遍历一个三角阵 ,但是,竟然忘记了为 j 增加偏置量(将 arr[j+i+1] 错写成 arr[j] ),导致报错,非常可惜。
5333. 制造字母异位词的最小步骤数
很简答的一道题,在理解“字母异位词”时有偏差,导致做得慢了。
def minSteps(self, s: str, t: str) -> int:
s_s = dict()
t_s = dict()
count = 0
for char in s:
s_s.setdefault(char, 0)
s_s[char] += 1
for char in t:
s_s.setdefault(char, 0)
s_s[char] -= 1
if s_s[char] < 0:
count += 1
return count
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
上面是我的解决方案,就是对两个 str() 的每个字母查数,因此分别建两个哈希表 dict() 就行了。字母不够的话, count++ ,最后返回 count 。
5334. 推文计数
头一次见到“设计一个类”的问题,开始时有被吓到,实际上非常简单。
class TweetCounts:
def __init__(self):
# (name, [time_list])
self.info = dict()
def recordTweet(self, tweetName: str, time: int) -> None:
self.info.setdefault(tweetName, list())
self.info[tweetName].append(time)
def getTweetCountsPerFrequency(self, freq: str, tweetName: str, startTime: int, endTime: int):
delta = 60
if freq == "minute":
delta = 60
if freq == "hour":
delta = 60 * 60
if freq == "day":
delta = 60 * 60 * 24
rts = list()
import math
count = math.ceil((endTime - startTime + 1) / delta)
count = max(1, count)
time_list = self.info[tweetName]
for i in range(count):
start = startTime + i * delta
end = min(start + delta, endTime + 1)
c = 0
for time in time_list:
if start <= time < end:
c += 1
rts.append(c)
if len(rts) == 0:
return 0
return rts
# Your TweetCounts object will be instantiated and called as such:
# obj = TweetCounts()
# obj.recordTweet(tweetName,time)
# param_2 = obj.getTweetCountsPerFrequency(freq,tweetName,startTime,endTime)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
我的解决方案如上,时间花在了阅读理解上,很不值得,其实不应该想太多:这种题,不会太难,因此往简单了想就好。
开始时,有些偷懒,按照如下思想设置了“存储-查找”规则:
# [(name, time)]
self.info = list()
# search
for n, t in self.info:
if n == tweetName and start_time <= t <= end_time:
rts += 1
- 1
- 2
- 3
- 4
- 5
- 6
这实际上是非常不科学的,我也因此复出了代价:
- 尽管逻辑上没有错误,但是查找每个用户,都需要对所有
info进行查找,浪费时间; - 因此提交代码后,报错(大量数据下,运行超时)。
我将哈希映射引入,来解决这个问题,如下。
# (name, [time_list])
self.info = dict()
# search
for t in self.info[tweetName]:
if start_time <= t <= end_time:
rts += 1
- 1
- 2
- 3
- 4
- 5
- 6
看来: 起码的时间复杂度还是要考虑,不能差的离谱。
5335. 参加考试的最大学生数
最后一题给我的第一感觉很明确:广度优先搜索 BFS。
但是问题是,没有起点。那索性就把所有的可用点当成起点,都来一遍。
BFS 可以用递归来写,但这着实花了我一些时间。我的解决方案如下。
def maxStudents(self, seats) -> int:
xL = len(seats)
yL = len(seats[0])
useable = list()
for i in range(xL):
for j in range(yL):
if seats[i][j] != '#':
useable.append((j, i))
def ok(a, b):
if a[0] - 1 == b[0] and (a[1] == b[1] or a[1] + 1 == b[1]):
return False
if a[0] + 1 == b[0] and (a[1] == b[1] or a[1] + 1 == b[1]):
return False
if b[0] + 1 == a[0] and (b[1] == a[1] or b[1] + 1 == a[1]):
return False
if b[0] - 1 == a[0] and (b[1] == a[1] or b[1] + 1 == a[1]):
return False
return True
rts = set()
def bfs(seat, used_list, notused_list, count):
if notused_list is None:
rts.add(count)
return
used_list = used_list.copy()
notused_list = notused_list.copy()
for nextSeat in notused_list:
seat_ok = True
for s in used_list:
if not ok(s, nextSeat):
seat_ok = False
if seat_ok:
count += 1
used_list.append(nextSeat)
notused_list.remove(nextSeat)
bfs(nextSeat, used_list, notused_list, count)
rts.add(count)
return
for s in useable:
tmp = useable.copy()
tmp.remove(s)
bfs(s, [s], tmp, 1)
return max(rts)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
因为时间紧迫+思路其实并不明晰,犯了不少“马虎”的毛病,如没有分清数组元素与横纵坐标的关系,将 useable.append((j, i)) 中的 i j 写反、忘了测试全为 '#' 的特殊例子等。
除此之外,我认为我在上面展示的方案是正确解决方案,但是提交时“报错”了,原因为“超时”。
我试了一下,确实太慢了,在本地,运行下面的例子也需要3秒左右:
[[".",".","#","#",".","#","#"],["#","#","#",".","#","#","."],
[".","#",".","#",".","#","."],[".","#",".","#",".",".","#"],
[".",".","#","#",".","#","."],["#",".","#","#",".","#","#"]]
- 1
- 2
- 3
但是能运行出来,说明算法没错(没有陷入死循环)。
我准备今天休息一下,下周看看别人的正确的解决方案。我还是比较疑惑的,因为按照我的经验,经典的 bfs 陷入了这种维度爆炸的困境,那可能说明精确解法已经不好使了。但是这道题是 LeetCode 题目,则其一定有很快的精确解法。
3. 比赛经验:调试环境与屏蔽干扰!
我这次在本地建了一个 .py 文件,直接在本地调试,节省线上调试的网络传输时间。
class Solution:
def checkIfExist(self, arr) -> bool:
...
solution = Solution()
arr = test_data_1
arr = test_data_2
# arr = test_data_3
print(solution.checkIfExist(arr))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
比赛时 QQ 、微信开始闪,我觉得对我没什么影响,就没有去管;但是到了后面时间紧张的时候,这很闹心,因此,我选择关掉这两个程序。实际上,以后应该从一开始就关闭。
进步还是不少的,大概总结这么多,下周想起来的话,可以再来一次。客观估计,结果不会变差,只会保持或者更好。从题目难度来看,目前没必要刻意去刷 LeetCode 。
PiperLiu
2020-2-9 15:28:14

所属网站分类: 技术文章 > 博客
作者:我下面给你吃
链接:https://www.pythonheidong.com/blog/article/231012/01740e98438034857bdc/
来源:python黑洞网
任何形式的转载都请注明出处,如有侵权 一经发现 必将追究其法律责任
3
0
收藏该文
昵称:
评论内容:(最多支持255个字符)
---无人问津也好,技不如人也罢,你都要试着安静下来,去做自己该做的事,而不是让内心的烦躁、焦虑,坏掉你本来就不多的热情和定力
站长公众号(new)
更多>
pdf(new)
更多>
问答(new)
更多>
游戏(new)
更多>