

机器学习主成分分析算法 PCA—python详细代码解析(sklearn)
发布于2024-11-01 21:48 阅读(1282) 评论(0) 点赞(17) 收藏(4)
一、问题背景
在进行数据分析时,我们常常会遇到这样的情况:各个特征变量之间存在较多的信息重叠,也就是相关性比较强。就好比在研究一个班级学生的学习情况时,可能会收集到学生的语文成绩、数学成绩、英语成绩等多个特征变量。但往往会发现,语文成绩好的学生,数学和英语成绩也可能比较好,这就说明这些变量之间存在一定的相关性。这种情况在线性回归分析中被称为多重共线性关系。
同时,如果我们的样本观测值数量较少,而选取的变量却很多,就会产生高维数据带来的 “维度灾难” 问题。想象一下,我们在一个三维空间中可以比较容易地理解和分析数据点的分布情况,但如果数据的维度增加到几十个甚至上百个,我们就很难直观地理解数据的结构和关系了。这就像是模型的自由度太小,构建效果自然就欠佳。
二、主成分分析算法的作用 —— 降维
为了解决这个问题,我们就需要用到降维的方法。主成分分析算法就是一种非常有效的降维手段。它针对有过多特征变量的数据集,在尽可能不损失信息或者少损失信息的情况下,将多个特征变量减少为少数几个潜在的主成分。
例如,在研究学生学习情况的例子中,主成分分析可能会将语文成绩、数学成绩、英语成绩等多个特征变量整合为几个主成分,比如综合学习能力主成分、学习努力程度主成分等。这几个主成分可以高度概括数据中的信息,既减少了变量个数,又能最大程度地保留原有特征变量中的信息。
三、主成分分析算法的基本原理
-
统计过程
主成分分析是一种降维分析的统计过程。它通过正交变换将原始的 n 维数据集变换到一个新的被称作主成分的数据集中。这个过程就像是对数据进行了一次 “重新排列”,把原本复杂的数据变得更加简洁和易于理解。 -
整合特征变量
在这个新的数据集中,众多的初始特征变量被整合成少数几个相互无关的主成分特征变量。这些新的特征变量尽可能地包含了初始特征变量的全部信息。比如,在学生学习情况的例子中,主成分分析可能会把语文成绩、数学成绩、英语成绩等多个特征变量整合为综合学习能力主成分和学习努力程度主成分。这两个主成分之间相互独立,不再像原始特征变量那样可能存在相关性。 -
代替原始变量进行分析
我们可以用这些新的特征变量来代替以前的特征变量进行分析。比如在线性回归分析算法中,如果遇到样本个数小于变量个数的高维数据情形,或者原始特征变量之前存在较强相关性造成多重共线性的情况,我们可以先进行主成分分析,以提取的主成分作为新的特征变量,再进行线性回归分析等监督式学习。 -
正交变换
主成分分析法从原始特征变量到新特征变量是一个正交变换(坐标变换)。通过正交变换,将原随机向量(分量间有相关性)转换成新随机向量(分量间不具有相关性),也就是将原随机向量的协方差矩阵变换成对角矩阵。这就像是把一堆杂乱无章的线整理成相互垂直的方向,使得每根线都独立不干扰。 -
最大方差原则
变换后的结果中,第一个主成分具有最大的方差值,每个后续的主成分在与前述主成分正交的条件限制下也具有最大方差。方差可以理解为数据的分散程度,方差越大,说明这个主成分包含的信息越多。所以,主成分分析会按照方差从大到小的顺序提取主成分。 -
降维保留信息
降维时仅保存前 m(m<n)个主成分即可保持最大的数据信息量。这是因为前面的主成分包含了大部分的数据信息,后面的主成分可能只包含少量的噪声或者冗余信息。通过只保留前几个主成分,我们可以在减少变量个数的同时,最大程度地保留原有特征变量中的信息。
四、确定主成分个数的方法
-
累积方差贡献率标准
如果从尽可能保持原始特征变量信息的角度出发,最终选取的主成分的个数可以通过各个主成分的累积方差贡献率来确定。一般情况下,以累积方差贡献率大于或等于 85% 为标准。这就意味着,我们选择的主成分能够解释原始数据中至少 85% 的方差。比如,在学生学习情况的例子中,如果我们通过主成分分析得到了三个主成分,它们的方差贡献率分别为 50%、20% 和 15%,那么累积方差贡献率就是 85%。这说明这三个主成分能够较好地概括原始数据中的信息。 -
直接限定主成分个数
如果单纯从降维的角度出发,可以直接限定提取的主成分的个数,以达到降维效果为目的,保留主成分。比如,我们原本有十个特征变量,为了降低数据的维度,可以直接设定提取三个主成分。
五、主成分分析算法的数学概念
假设原始特征向量 X=(X1,X2,…,Xp) T 是一个 p 维随机特征向量,首先将其标准化为 ZX=(ZX1,ZX2,…,ZXp) T,使得每一个变量的平均值为 0,方差为 1。
为什么要进行标准化呢?这是因为如果变量之间的方差差别较大,主成分分析就会被较大方差的变量所主导,使得分析结果严重失真。比如,在学生学习情况的例子中,如果语文成绩的方差远远大于数学成绩和英语成绩的方差,那么在主成分分析中,语文成绩就会占据主导地位,从而影响分析结果的准确性。
六、主成分的特征值
-
解释能力
主成分的特征值可以代表该主成分的解释能力。特征值是方差的组成部分,所有主成分的特征值加起来就是分析中主成分的方差之和,即主成分的 “总方差”。
例如,针对 10 个原始特征变量提取了 10 个主成分,10 个主成分的总方差就是 10。在某次分析中,第一个主成分的特征值为 6.61875,其方差贡献率就是 66.19%(6.61875/10),或者说该主成分能够解释总方差的 66.19%;第二个主成分的特征值为 1.47683,其方差贡献率就是 14.77%(1.47683/10),或者说该主成分能够解释总方差的 14.77%。
-
确定主成分个数的标准
特征值越大,解释能力越强。通常情况下,只有特征值大于 1 的主成分是有效的。因为平均值就是 1(结合前面讲解的 10 个主成分的总方差就是 10 来理解),如果某主成分的特征值低于 1,则说明该主成分对于方差的解释还没有达到平均水平,所以不建议保留。该方法也可以用来作为 “确定主成分个数” 的判别标准。
七、样本的主成分得分
每个样本主成分的具体取值称为主成分得分。在主成分分析中,我们通过计算每个样本在各个主成分上的得分,来确定样本在新的特征空间中的位置。
比如,在学生学习情况的例子中,我们通过主成分分析得到了两个主成分:综合学习能力主成分和学习努力程度主成分。对于每个学生,我们可以计算出他们在这两个主成分上的得分。如果一个学生在综合学习能力主成分上的得分较高,而在学习努力程度主成分上的得分较低,那么我们就可以认为这个学生的综合学习能力较强,但学习努力程度可能不够。
八、主成分载荷
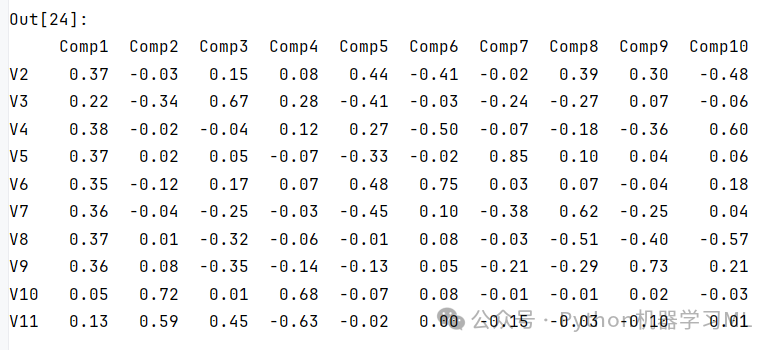
主成分载荷表示每个变量对于主成分的影响,常用特征向量矩阵来表示。每个主成分荷载的列式平方和为 1。
例如,在学生学习情况的例子中,主成分载荷可以告诉我们语文成绩、数学成绩、英语成绩等各个变量对于综合学习能力主成分和学习努力程度主成分的影响程度。如果语文成绩对于综合学习能力主成分的载荷较大,那么说明语文成绩在很大程度上影响了学生的综合学习能力。
具体案例
以 “中国 2021 年 1~3 月份地区主要能源产品产量统计” 数据为例,深入剖析主成分分析全过程。从导入模块函数到变量设置与数据处理,再到特征变量相关性分析、主成分提取及各类计算,更有直观的碎石图观察各主成分变化,最后计算样本主成分得分并绘制二维、三维图形展示。
1 案例数据说明
以“数据11.1”文件中的数据为例进行讲解,其中记录的是“中国2021年1~3月份地区主要能源产品产量统计”,数据摘编自《中国经济景气月报》(2021年04月刊)。该数据文件中共有21个变量,是V1~V21,分别代表地区、汽油万吨、煤油万吨、柴油万吨、燃料油万吨、石脑油万吨、液化石油气万吨、石油焦万吨、石油沥青万吨、焦炭万吨、煤气亿立方米、火力发电量亿千瓦/小时、水力发电量亿千瓦/小时、核能发电量亿千瓦/小时、风力发电量亿千瓦/小时、太阳能发电量亿千瓦/小时、原煤万吨、原油万吨、天然气亿立方米、煤层气亿立方米、液化天然气万吨。
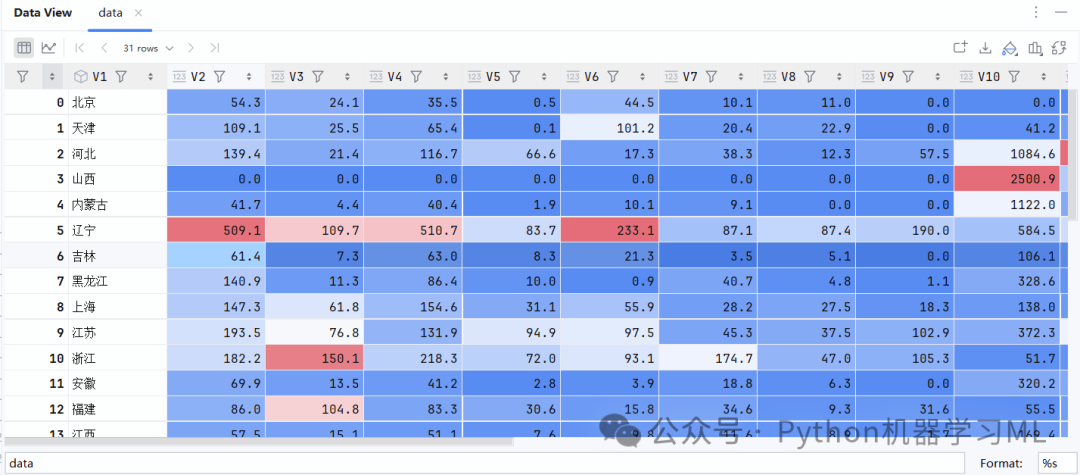
下面我们针对V2(汽油万吨)、V3(煤油万吨)、V4(柴油万吨)、V5(燃料油万吨)、V6(石脑油万吨)、V7(液化石油气万吨)、V8(石油焦万吨)、V9(石油沥青万吨)、V10(焦炭万吨)、V11(煤气亿立方米)共10个变量开展主成分分析。
2 导入分析所需要的模块和函数
在进行分析之前,首先需要导入分析所需要的模块和函数,读取数据集并进行观察。
#主成分分析算法#载入分析所需要的模块和函数import numpy as npimport pandas as pdimport matplotlib.pyplot as pltimport seaborn as snsfrom sklearn.preprocessing import StandardScalerfrom sklearn.decomposition import PCA3 变量设置及数据处理
filepath="数据11.1.csv"data=pd.read_csv(filepath)X = data.iloc[:,1:11]#设置分析所需要的特征变量X.info()len(X.columns) X.columns X.shapeX.dtypesX.isnull().values.any() X.isnull().sum() X.head(10)
在主成分分析算法中,需要对参与分析的特征变量进行标准化。
scaler = StandardScaler()scaler.fit(X)X_s = scaler.transform(X)X_s = pd.DataFrame(X_s, columns=X.columns)4 特征变量相关性分析
print(X_s.corr(method='pearson')) plt.subplot(1,1,1)sns.heatmap(X_s.corr(), annot=True)可以发现很多变量之间的相关性水平都非常高,体现在变量之间的相关性系数都非常大,变量之间存在着较强的正自相关,比较适合用于主成分分析。
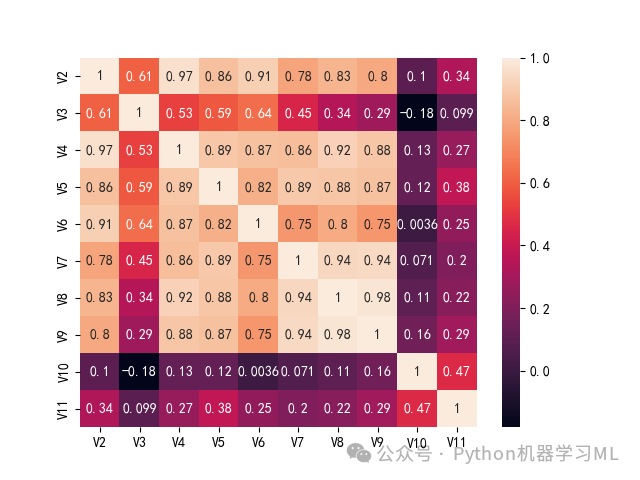
热力图的右侧为图例说明,颜色越深表示相关系数越小,颜色越浅表示相关系数越大;左侧的矩阵则形象地展示了各个变量之间的相关情况。
5 主成分提取及特征值、方差贡献率计算
model = PCA()#将模型设置为主成分分析算法model.fit(X_s)#基于X_s的数据,使用fit方法进行拟合np.set_printoptions(suppress=True)#不以科学计数法显示,而是直接显示数字model.explained_variance_#计算提取的各个主成分的特征值model.explained_variance_ratio_#计算各主成分的方差贡献率
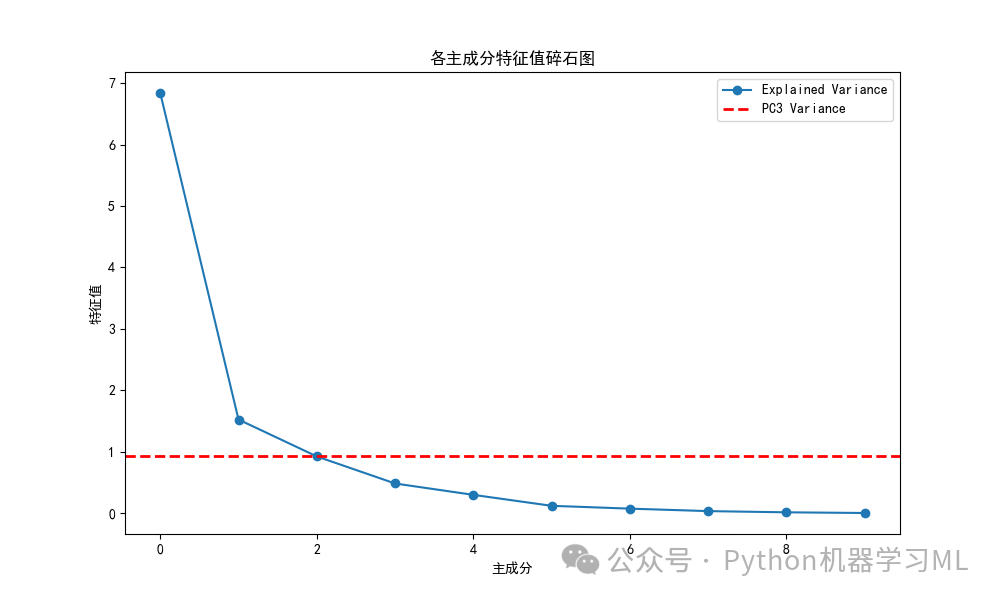
可以发现各个主成分的特征值是降序排列的,提取的第一个主成分的特征值最大,为6.83937558,然后越来越小,并且只有前两个主成分的特征值是大于1的。

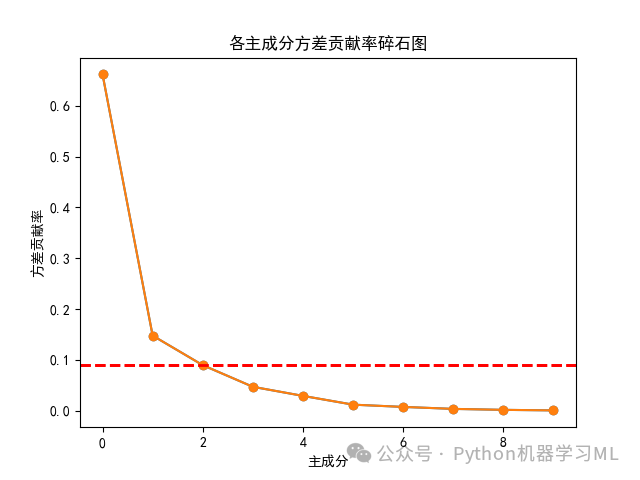
可以发现各个主成分的方差贡献率也是降序排列的,提取的第一个主成分的方差贡献率最大,为0.66187506,可以理解为该主成分解释了所有原始特征变量66.19%的信息;第2个主成分的方差贡献率为0.1477,可以理解为该主成分解释了所有原始特征变量14.77%的信息;以此类推。
6 绘制碎石图观察各主成分特征值
import matplotlib.pyplot as plt# 确保model.explained_variance_是一个一维数组print(model.explained_variance_)# 绘制碎石图观察各主成分特征值plt.figure(figsize=(10, 6)) # 可以设置图形的大小plt.plot(model.explained_variance_, 'o-', label='Explained Variance')# 绘制红色虚线,表示第三个主成分的特征值plt.axhline(model.explained_variance_[2], color='r', linestyle='--', linewidth=2, label='PC3 Variance')# 解决图表中中文显示问题plt.rcParams['font.sans-serif'] = ['SimHei']# 将图中x轴的标签设置为'主成分'plt.xlabel('主成分')# 将图中y轴的标签设置为'特征值'plt.ylabel('特征值')# 将图的标题设置为'各主成分特征值碎石图'plt.title('各主成分特征值碎石图')# 显示图例plt.legend()# 显示图形plt.show()# 保存图形为PNG文件plt.savefig('各主成分特征值碎石图.png')可以非常直观地看出各主成分特征值的变化情况。在第二个主成分处出现拐点。
7 绘制碎石图观察各主成分方差贡献率
plt.plot(model.explained_variance_ratio_, 'o-')plt.axhline(model.explained_variance_ratio_[2], color='r', linestyle='--', linewidth=2)plt.xlabel('主成分')#将图中x轴的标签设置为'主成分'plt.ylabel('方差贡献率')#将图中y轴的标签设置为'方差贡献率'plt.title('各主成分方差贡献率碎石图')#将图的标题设置为'各主成分方差贡献率碎石图'plt.show()plt.savefig('各主成分方差贡献率碎石图.png')可以非常直观地看出各主成分方差贡献率的变化情况。在第二个主成分处出现拐点。
8 绘制碎石图观察主成分累积方差贡献率
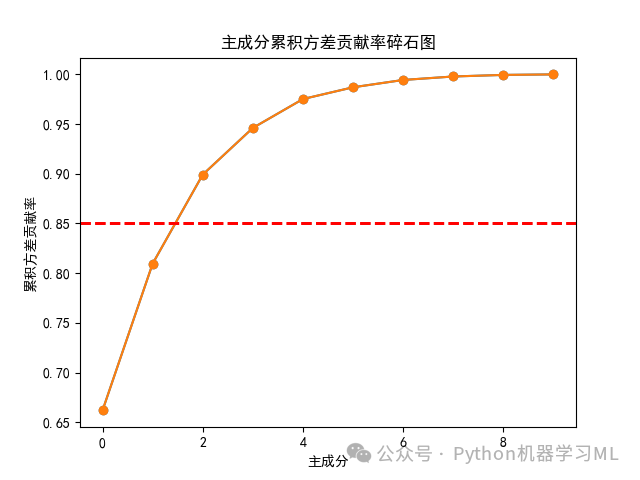
可以发现当提取主成分个数为2时,没有超过85%的红线,而当提取主成分个数为3时,就超过了85%的红线,也就是说,如果我们将“累积方差贡献率大于或等于85%”作为选取主成分的标准,那么仅提取前三个主成分即可。
9 计算样本的主成分得分
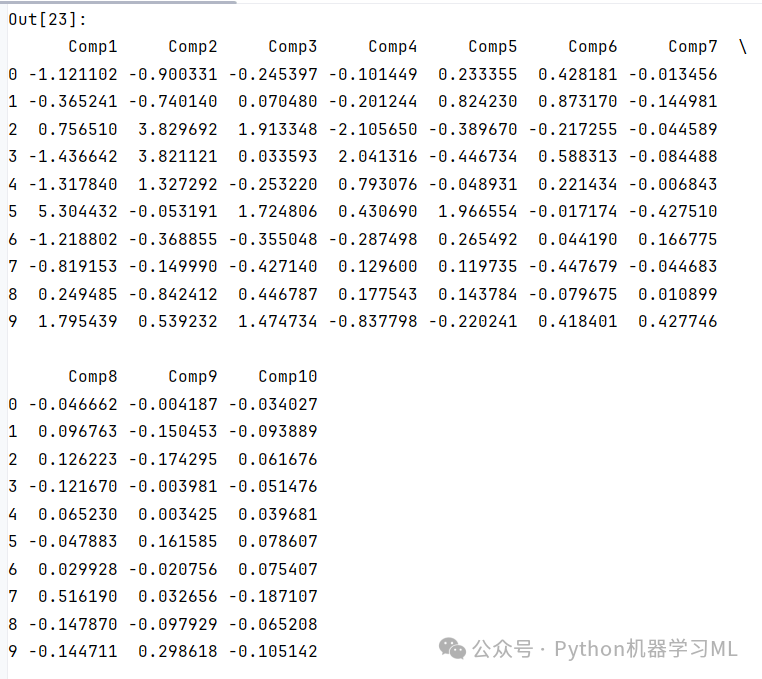
10 绘制二维图形展示样本在前两个主成分上的得分
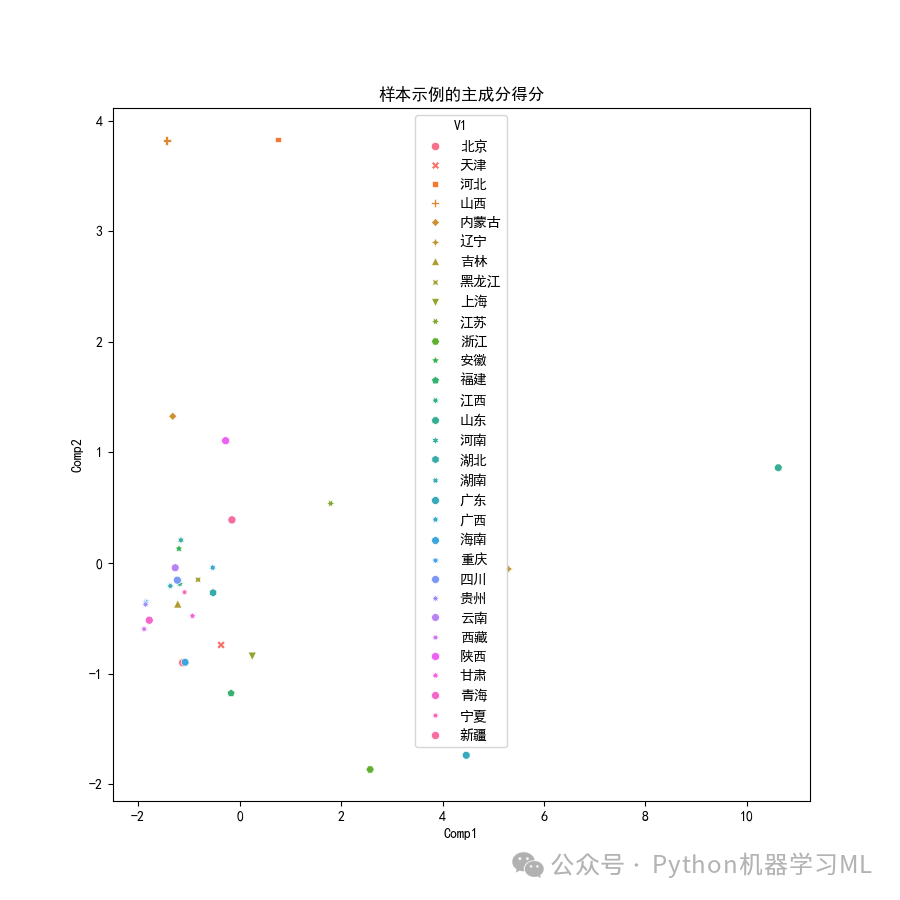
11 绘制三维图形展示样本在前三个主成分上的得分
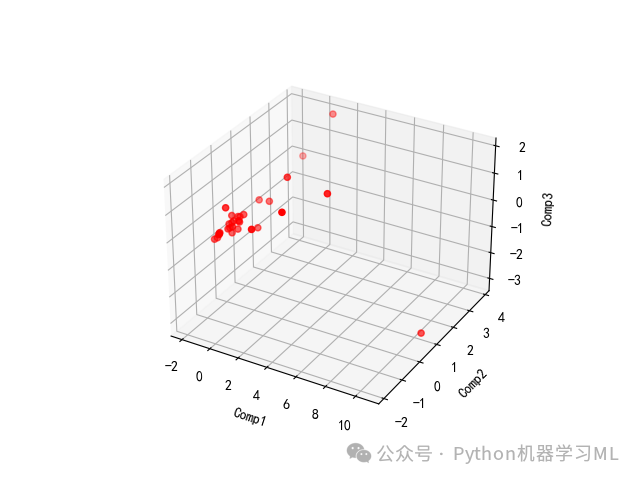
12 输出特征向量矩阵,观察主成分载荷
需要数据集请关注公众号:Python机器学习ML 回复 数据
所属网站分类: 技术文章 > 博客
作者:sjhjf0293
链接:https://www.pythonheidong.com/blog/article/2040816/39e63754b4aabd2af7a4/
来源:python黑洞网
任何形式的转载都请注明出处,如有侵权 一经发现 必将追究其法律责任
昵称:
评论内容:(最多支持255个字符)
---无人问津也好,技不如人也罢,你都要试着安静下来,去做自己该做的事,而不是让内心的烦躁、焦虑,坏掉你本来就不多的热情和定力