

Python之Scrapy初学问题集中(三):难道爬取的网站对我有意见!!!
发布于2020-03-15 19:46 阅读(1876) 评论(0) 点赞(30) 收藏(1)
开篇的牢骚
你有没有自己边学习,边练习,但是案例代码在自己手中也是时不时的出现问题?你会想是这个网站对你有意见吗?
其实不然,随着爬虫的进行,反爬技术也在不停地更新换代,对付我这种小白级人物,只要随便修改写网页标签,就会将我难得,大呼“悲哉”。
案例代码已经是几个月前或几年前的了,所以那些代码的参考性只在结构上,而不是实际的代码上。
如果你也碰到过这样的问题,就和我一起看看,我发现的问题吧!!!
出现问题的初始代码
from scrapy import Request
from scrapy.spiders import Spider
from shetu_spider.items import ShetuSpiderItem
class image_download(Spider):
name = 'image'
def start_requests(self):#初始请求
url = 'http://699pic.com/photo/'
yield Request(url)
def parse(self, response):#解析函数-图片列表页
urls = response.xpath("//div[@class='pl-list']/a[1]/@href").extract()
for i in range(len(urls)):
yield Request(urls[i],callback=self.parse_image)
def parse_image(self,response):
item = ShetuSpiderItem()
#获取所有图片url地址
urls = response.xpath("//li[@class='list']/a/img/@data-original").extract()
if urls:
title = response.xpath("//li[@class='list']/a/img/@title").extract()
item['title'] = title
item['image_urls']=urls
yield item
#获取下一页地址
next_url = response.xpath("//a[@class='downPage']/@href").extract()
if next_url:
next_url = response.urljoin(next_url[0])
yield Request(next_url,callback=self.parse_image)
上面的代码就是案例的实际代码。下面就先拿出网页已修改的地方。
问题一: Missing scheme in request url:xxx.html
ValueError: Missing scheme in request url: //699pic.com/zhuanti/baiseqingrenjie.html
几个月前的页面:
这张是列表页上的:
 这张是详细图片页上的。
这张是详细图片页上的。

现在的页面
列表页
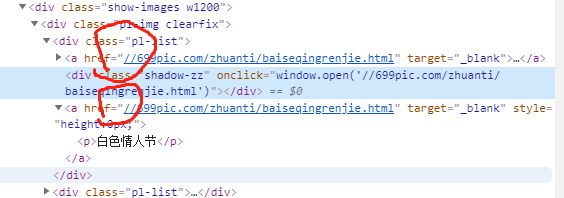
详情页
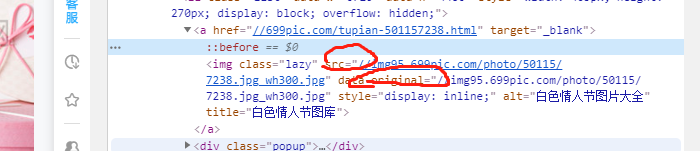
明显的出现,这样的一点变化。
就直接导致了下面的的一个问题1
ERROR: Spider error processing <GET http://699pic.com/photo/> (referer: None)
Traceback (most recent call last):
File "G:\python\Anaconda3\lib\site-packages\scrapy\utils\defer.py", line 102, in iter_errback
yield next(it)
File "G:\python\Anaconda3\lib\site-packages\scrapy\spidermiddlewares\offsite.py", line 29, in process_spider_output
for x in result:
File "G:\python\Anaconda3\lib\site-packages\scrapy\spidermiddlewares\referer.py", line 339, in <genexpr>
return (_set_referer(r) for r in result or ())
File "G:\python\Anaconda3\lib\site-packages\scrapy\spidermiddlewares\urllength.py", line 37, in <genexpr>
return (r for r in result or () if _filter(r))
File "G:\python\Anaconda3\lib\site-packages\scrapy\spidermiddlewares\depth.py", line 58, in <genexpr>
return (r for r in result or () if _filter(r))
File "G:\MyScrapy\shetu_spider\shetu_spider\spiders\image_spider.py", line 15, in parse
yield Request(urls[i],callback=self.parse_image)
File "G:\python\Anaconda3\lib\site-packages\scrapy\http\request\__init__.py", line 25, in __init__
self._set_url(url)
File "G:\python\Anaconda3\lib\site-packages\scrapy\http\request\__init__.py", line 62, in _set_url
raise ValueError('Missing scheme in request url: %s' % self._url)
ValueError: Missing scheme in request url: //699pic.com/zhuanti/baiseqingrenjie.html
ValueError: Missing scheme in request url: //699pic.com/zhuanti/baiseqingrenjie.html
问题出在你的图片地址不完整,实际中浏览器的地址栏可以直接写这个地址,但是scrapy爬虫需要的是完整的url地址,这就是必出错。
问题二:Missing scheme in request url: h
ValueError: Missing scheme in request url: h,这个问题是在我解决完第一个问题之后出现的。
网上也有不少原理上的解决方法。就是说,你的image_url不是数组,但是我的情况是image_url是一个数组,与网上的问题有些出入。下面给出我的解决方案
ERROR: Error processing {'image_urls': 'http://img95.699pic.com/photo/50141/1132.jpg_wh300.jpg',
'title': '运动健康图库'}
Traceback (most recent call last):
File "G:\python\Anaconda3\lib\site-packages\twisted\internet\defer.py", line 654, in _runCallbacks
current.result = callback(current.result, *args, **kw)
File "G:\python\Anaconda3\lib\site-packages\scrapy\pipelines\media.py", line 79, in process_item
requests = arg_to_iter(self.get_media_requests(item, info))
File "G:\MyScrapy\shetu_spider\shetu_spider\pipelines.py", line 17, in get_media_requests
return [Request(x,meta={'title':item['title']}) for x in item.get(self.images_urls_field, [])]
File "G:\MyScrapy\shetu_spider\shetu_spider\pipelines.py", line 17, in <listcomp>
return [Request(x,meta={'title':item['title']}) for x in item.get(self.images_urls_field, [])]
File "G:\python\Anaconda3\lib\site-packages\scrapy\http\request\__init__.py", line 25, in __init__
self._set_url(url)
File "G:\python\Anaconda3\lib\site-packages\scrapy\http\request\__init__.py", line 62, in _set_url
raise ValueError('Missing scheme in request url: %s' % self._url)
ValueError: Missing scheme in request url: h
两个问题的解决方案+完整代码
问题取决于第一个问题解决,之后发现,传的url地址是数组,但是还是缺少了“http:”,所以就有如下的代码:(注释掉的是问题代码)
spider.py
from scrapy import Request
from scrapy.spiders import Spider
from shetu_spider.items import ShetuSpiderItem
class image_download(Spider):
name = 'image'
def start_requests(self):#初始请求
url = 'http://699pic.com/photo/'
yield Request(url)
def parse(self, response):#解析函数-图片列表页
urls = response.xpath("//div[@class='pl-list']/a[1]/@href").extract()
for i in range(len(urls)):
# yield Request(urls[i],callback=self.parse_image)
yield Request(('http:'+urls[i]),callback=self.parse_image)
def parse_image(self,response):
item = ShetuSpiderItem()
#获取所有图片url地址
urls = response.xpath("//li[@class='list']/a/img/@data-original").extract()
# if urls:
# title = response.xpath("//li[@class='list']/a/img/@title").extract_first()
# item['title'] = title
# item['image_urls']=urls
# yield item
for url in urls:
url = 'http:'+url
if url:
title = response.xpath("//li[@class='list']/a/img/@title").extract_first()
item['title'] = [title]
item['image_urls']=[url]
yield item
#获取下一页地址
next_url = response.xpath("//a[@class='downPage']/@href").extract()
if next_url:
next_url = response.urljoin(next_url[0])
yield Request(next_url,callback=self.parse_image)
items.py
import scrapy
class ShetuSpiderItem(scrapy.Item):
# define the fields for your item here like:
image_urls = scrapy.Field()#图片url的地址-列表
images = scrapy.Field()#存储图片下载信息
title = scrapy.Field()#主题名称
settings.py
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.132 Safari/537.36'
ROBOTSTXT_OBEY = False
#设置图片下载路径
IMAGES_STORE = "./摄图网图片"
#设置缩略图大小
IMAGES_THUMBS={
'small':(30,30),
'big':(50,50),
#过滤尺寸过小的图片
IMAGES_MIN_WIDTH=10
IMAGES_MIN_HEIGHT=10
#通道是自己自定义的SaveImagePipeline,不是默认的
ITEM_PIPELINES = {
'shetu_spider.pipelines.SaveImagePipeline': 300,
}
pipelines.py
from scrapy.pipelines.images import ImagesPipeline
from scrapy import Request
class ShetuSpiderPipeline(object):#默认的通道
def process_item(self, item, spider):
return item
class SaveImagePipeline(ImagesPipeline):#自定义的通道
def get_media_requests(self, item, info):#图片下载的请求
return [Request(x,meta={'title':item['title']}) for x in item.get(self.images_urls_field, [])]
def file_path(self,request,response=None,info=None):#设置图片存储路径及名称
title = request.meta['title']
image_name = request.url.split('/')[-1]
return "%s/%s"%(title,image_name)
def thumb_path(self, request, thumb_id, response=None, info=None):#设置缩略图路径及名称
title = request.meta['title']
image_name = request.url.split('/')[-1]
return "%s/%s/%s" % (title,thumb_id, image_name)
start.py ( 免除了一直命令窗口输入指令的麻烦事)
from scrapy import cmdline
cmdline.execute("scrapy crawl image -o image.csv".split())
爬取成功

祝大家爬虫成功,敲出更多的BUG,克服每一个BUG,让自己做一个优秀的没有BUG的程序员!!!我是新生代程序员“敲出亿行bug”
原文链接:https://blog.csdn.net/wenquan19960602/article/details/104860522
所属网站分类: 技术文章 > 博客
作者:恋爱后女盆友的变化
链接:https://www.pythonheidong.com/blog/article/260273/591b47af85ce7669c086/
来源:python黑洞网
任何形式的转载都请注明出处,如有侵权 一经发现 必将追究其法律责任
昵称:
评论内容:(最多支持255个字符)
---无人问津也好,技不如人也罢,你都要试着安静下来,去做自己该做的事,而不是让内心的烦躁、焦虑,坏掉你本来就不多的热情和定力