

机器(深度学习)新手第一次在Kaggle上被虐的经历(经验)——泰坦尼克号生存预测:Titanic: Machine Learning from Disaster——(上)
发布于2019-08-20 10:20 阅读(2354) 评论(0) 点赞(15) 收藏(2)
一点废话
就在一个天气晴朗的日子,我终于学完了达叔的深度学习课程,你们懂得,这时候都是贼认不清自己,认为可以上天了!!膨胀无比。啊哈哈 然后就在网上找一些下一步干什么的建议。大多数都是说可以去Kaggle做一点竞赛,所以我就翻了墙去搞一次试试,然后就发生了惊天惨案!!!!我谨把自己的想法,经历过的问题,以及解决方法写出来,比较基础。大神们请轻喷。这是上篇,只到第一次提交预测,后面的改进模型,特征的改进,都在下篇。
点击这里:机器(深度学习)新手第一次在Kaggle上被虐的经历(经验)——泰坦尼克号生存预测:Titanic: Machine Learning from Disaster——(下)
一.关于Kaggle的一些问题
1.kaggle网页不用翻墙,但是在注册的时候,会有确定邮箱环节,这时候必须要翻墙,因为其中的确认码会被墙,而这个确认码你是看不到的,也就是你没办法完成注册,所以你可以尝试翻墙或看这里:
解决kaggle邮箱验证不能confirm的问题
不过以后你去提交你的预测文档的时候你还是需要翻墙-,- 所以你懂的。
早翻墙 早享受 嘿嘿嘿
2.然后你需要有一个好的心态(反正我后来还是爆炸了)和好的指南。
心态:七大诀窍助你享受Kaggle竞赛
指南:你还想要啥指南,我这篇就是指南,给我继续读!!!
二.Titanic 下载数据集
所以你注册成功后 进到泰坦尼克号这个竞赛中
Titanic: Machine Learning from Disaster
你应该看到这个页面 你可以先看看相关的描述什么的,知道你在将要预测什么,和故事的背景:杰克和肉丝那个爱情故事,泰坦尼克号在自己的处女航里装冰山沉没,船上的救生艇根本不够,所以副船长发话:lady and kid first!
你可以先看看相关的描述什么的,知道你在将要预测什么,和故事的背景:杰克和肉丝那个爱情故事,泰坦尼克号在自己的处女航里装冰山沉没,船上的救生艇根本不够,所以副船长发话:lady and kid first!
我们要做的就是根据一些乘客的个人信息以及存活状况,要尝试根据它生成合适的模型并预测其他人的存活状况。
bingo!二分类问题,目标解决了。
然后点进Data然后你也可以看看数据集的描述什么的,看看每一个数据特征的意思。往下翻之后有一个下载数据的地方 右上角是可以下载他们的工具,然后在Anaconda prompt里用pip进行下载,不过我弄半天不知道是咋弄的挺麻烦,后来我无意发现他喵的左边可以直接在浏览器里下载,MMP。要鼠标放上去才会显示,我们最爱的下载符号,啊哈哈!
右上角是可以下载他们的工具,然后在Anaconda prompt里用pip进行下载,不过我弄半天不知道是咋弄的挺麻烦,后来我无意发现他喵的左边可以直接在浏览器里下载,MMP。要鼠标放上去才会显示,我们最爱的下载符号,啊哈哈!
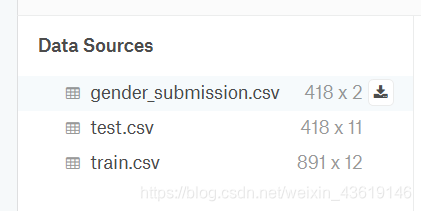
点了之后就可以下载了,第一个gender_submission.csv是提交的示例,告诉你提交的格式,test.csv是测试集,让你用模型预测了之后提交你的存活数据,train.csv是训练集,用来训练你的模型-。-
三.观察数据集以及特征工程
上来就想搭建模型?嘿嘿 我当时也是那么狂躁,但是发现确实不知道咋弄,一头雾水,所以还是先来看看数据集吧。

图是@快乐的佩奇 的,表示感谢 嘿嘿
看到这些还有实际数据肯定有点想法啊,客人等级,性别,年龄,还有船上亲人的数量,这几个肯定是和存活率有关的啊,还有姓名,编号,其他的什么暂时还不知道有没有关系,先放一下,重要的一个问题:年龄和客舱号都是缺失的,客舱号还不确定和存活有没有关系,但是年龄肯定有的,毕竟当时船长都说让女人和孩子先上救生船,所以填充年龄肯定是必须的。
不过不着急,反正用的python,画图那么简单,不画白不画图,一方面可以印证自己的猜测,一方面没准发现更深的联系!
导入一些库:
import pandas as pd
import numpy as np
from pandas import Series,DataFrame
import matplotlib.pyplot as plt
- 1
- 2
- 3
- 4
读入文件:
data_train = pd.read_csv("Train.csv")
#读入的文件是.csv的,放入了一个dataframe里。
- 1
- 2
所谓的dataframe其实也就是一个跟excel一样的表格形式的格式。
先让dataframe自己告诉我们一点信息:
data_train.info()
- 1
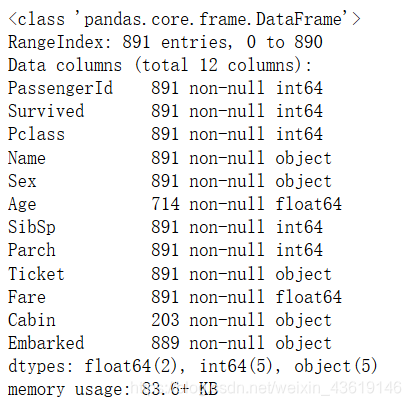
可以看到各个字段的名称和数据类型,还有就是Cabin,Age都有缺失。
现在要开始仔细看数据了
data_train
- 1
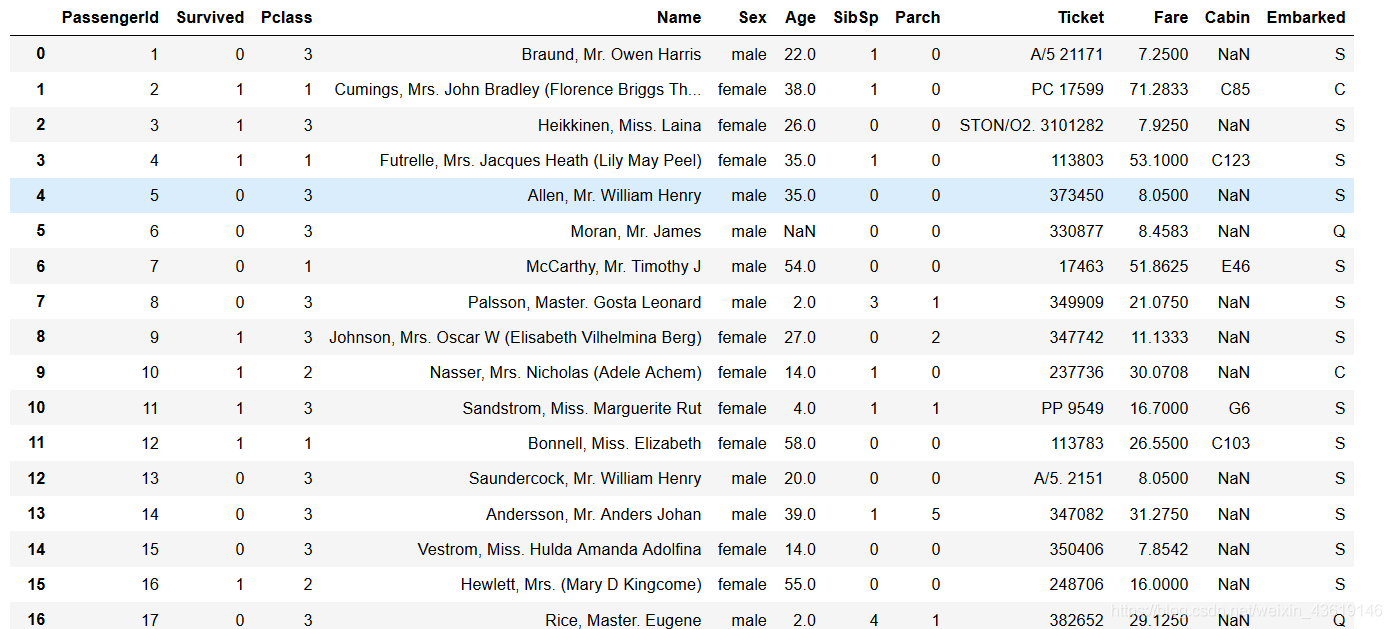 卧槽那么多,那么乱,看下去眼睛岂不是要废了,所以我们就要发挥一下python的优势了,画图!!!!
卧槽那么多,那么乱,看下去眼睛岂不是要废了,所以我们就要发挥一下python的优势了,画图!!!!
import matplotlib.pyplot as plt
fig = plt.figure()
fig.set(alpha=0.2) # 设定图表颜色alpha参数
plt.subplot2grid((2,3),(0,0)) # 在一张大图里分列几个小图
data_train.Survived.value_counts().plot(kind='bar')# 柱状图
plt.title(u"获救情况 (1为获救)") # 标题
plt.ylabel(u"人数")
plt.subplot2grid((2,3),(0,1))
data_train.Pclass.value_counts().plot(kind="bar")
plt.ylabel(u"人数")
plt.title(u"乘客等级分布")
plt.subplot2grid((2,3),(0,2))
plt.scatter(data_train.Survived, data_train.Age)
plt.ylabel(u"年龄") # 设定纵坐标名称
plt.grid(b=True, which='major', axis='y')
plt.title(u"按年龄看获救分布 (1为获救)")
plt.subplot2grid((2,3),(1,0), colspan=2)
data_train.Age[data_train.Pclass == 1].plot(kind='kde')
data_train.Age[data_train.Pclass == 2].plot(kind='kde')
data_train.Age[data_train.Pclass == 3].plot(kind='kde')
plt.xlabel(u"年龄")# plots an axis lable
plt.ylabel(u"密度")
plt.title(u"各等级的乘客年龄分布")
plt.legend((u'头等舱', u'2等舱',u'3等舱'),loc='best') # sets our legend for our graph.
plt.subplot2grid((2,3),(1,2))
data_train.Embarked.value_counts().plot(kind='bar')
plt.title(u"各登船口岸上船人数")
plt.ylabel(u"人数")
plt.show()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
emmm,如果你用的是jupyter画出的图,中文乱码,或者不显示的话,前面加上这几行:
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus']=False
- 1
- 2
- 3
就可以了。
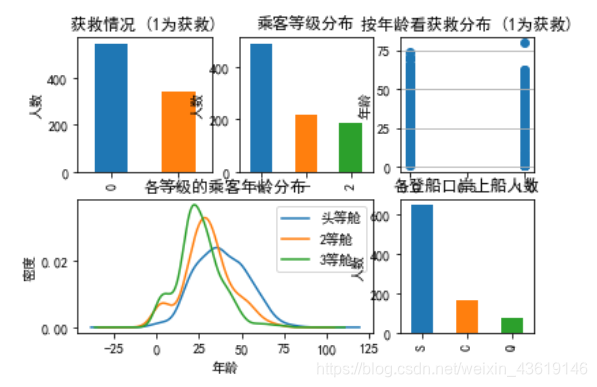
现在看看画的图,被救的不多,300多吧。三等舱的最多,获救的是什么年龄都有的,而明显一等舱的年龄都比较大(比较有钱,啧啧),s港口上船的最多。
再来看看资本对获救有没有影响:
#看看各乘客等级的获救情况
fig = plt.figure()
fig.set(alpha=0.2) # 设定图表颜色alpha参数
Survived_0 = data_train.Pclass[data_train.Survived == 0].value_counts()
Survived_1 = data_train.Pclass[data_train.Survived == 1].value_counts()
df=pd.DataFrame({u'获救':Survived_1, u'未获救':Survived_0})
df.plot(kind='bar', stacked=True)
plt.title(u"各乘客等级的获救情况")
plt.xlabel(u"乘客等级")
plt.ylabel(u"人数")
plt.show()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
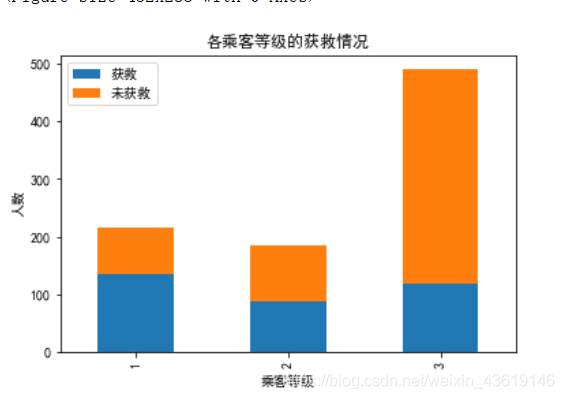
果然哈,有钱能使鬼推磨,资本让人存活哈,还是我们社会主义好,人人平等!核心主义价值观就有平等,哈哈!
看来乘客等级是个挺重要的特征。
再来看看性别的问题:
#看看各性别的获救情况
fig = plt.figure()
fig.set(alpha=0.2) # 设定图表颜色alpha参数
Survived_m = data_train.Survived[data_train.Sex == 'male'].value_counts()
Survived_f = data_train.Survived[data_train.Sex == 'female'].value_counts()
df=pd.DataFrame({u'男性':Survived_m, u'女性':Survived_f})
df.plot(kind='bar', stacked=True)
plt.title(u"按性别看获救情况")
plt.xlabel(u"性别")
plt.ylabel(u"人数")
plt.show()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
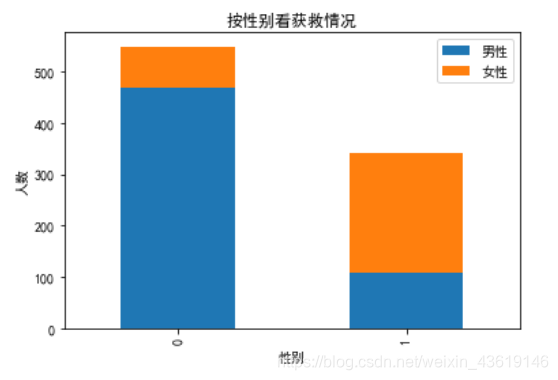
这,明显男同胞们牺牲的比较多,女同胞们还是收到了照顾!!印证了我们的猜测。
下面看看港口和家人有木有影响:
fig = plt.figure()
fig.set(alpha=0.2) # 设定图表颜色alpha参数
Survived_0 = data_train.Embarked[data_train.Survived == 0].value_counts()
Survived_1 = data_train.Embarked[data_train.Survived == 1].value_counts()
df=pd.DataFrame({u'获救':Survived_1, u'未获救':Survived_0})
df.plot(kind='bar', stacked=True)
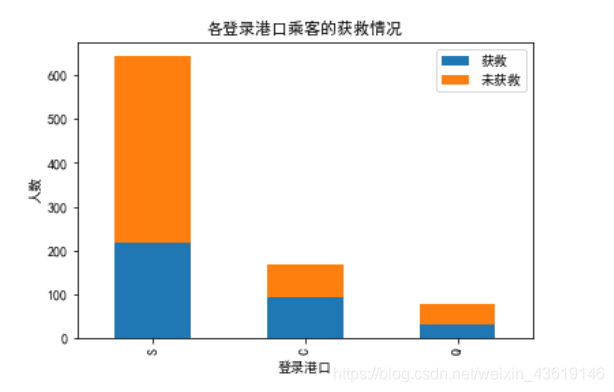
plt.title(u"各登录港口乘客的获救情况")
plt.xlabel(u"登录港口")
plt.ylabel(u"人数")
plt.show()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
g = data_train.groupby(['SibSp','Survived'])
df = pd.DataFrame(g.count()['PassengerId'])
print(df)
g = data_train.groupby(['SibSp','Survived'])
df = pd.DataFrame(g.count()['PassengerId'])
print(df)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
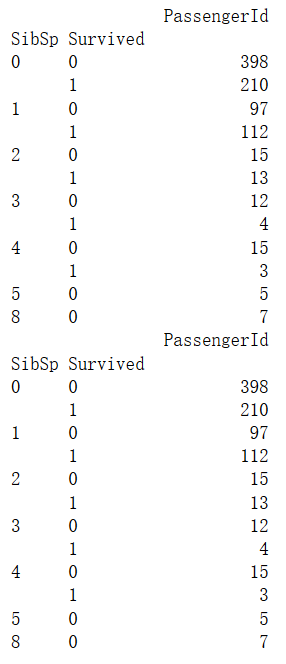
好像家人和登船的港口都有影响。家人多,有人伸援手,存活率高不奇怪,登船港口有联系是什么情况?难道是不同地方上船,在船的位置不同?船沉的时候,占有救援优势?不知道啊,先用着吧!
看看船舱有没有影响:
fig = plt.figure()
fig.set(alpha=0.2) # 设定图表颜色alpha参数
Survived_cabin = data_train.Survived[pd.notnull(data_train.Cabin)].value_counts()
Survived_nocabin = data_train.Survived[pd.isnull(data_train.Cabin)].value_counts()
df=pd.DataFrame({u'有':Survived_cabin, u'无':Survived_nocabin}).transpose()
df.plot(kind='bar', stacked=True)
plt.title(u"按Cabin有无看获救情况")
plt.xlabel(u"Cabin有无")
plt.ylabel(u"人数")
plt.show()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
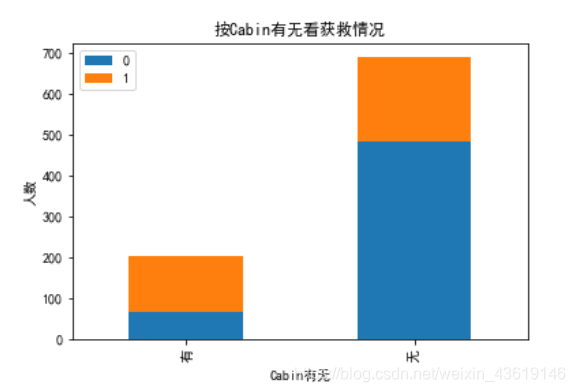
很明显有船舱记录的,获救可能性很大,不过肯定是因为许多遇难的人不太好找出他的船仓号,导致成活的人 船舱号多一些,也是猜测,到时候试验一下了。
OK!数据差不多看完了,现在觉得可以差不多开始预处理了!
四.数据预处理
因为这是第一次,虽然咱们有很多想法,但是先找一个比较简单的,先快速搭建起来,预处理也先用简单一点的:年龄先用平均值去填充。船舱号,名字这两个先不用呢。
1.训练集的预处理
#训练集的预处理
data = pd.read_csv('train.csv') #读取文件
data = data[['Survived', 'Pclass', 'Sex', 'Age', 'SibSp', 'Fare','Parch' ,'Embarked']] #筛选需要的列
data['Age'] = data['Age'].fillna(data['Age'].mean()) #平均值填充
data['Sex'] = [1 if x == 'male' else 0 for x in data.Sex] #男变为1女变为0
data['p1'] = np.array(data['Pclass'] == 1).astype(np.int32)#船舱等级变为三列
data['p2'] = np.array(data['Pclass'] == 2).astype(np.int32)
data['p3'] = np.array(data['Pclass'] == 3).astype(np.int32)
del data['Pclass'] #删除此列
data['e1'] = np.array(data['Embarked'] == 'S').astype(np.int32)#也变为三列
data['e2'] = np.array(data['Embarked'] == 'C').astype(np.int32)
data['e3'] = np.array(data['Embarked'] == 'Q').astype(np.int32)
del data['Embarked']
X_train = data[[ 'Sex', 'Age', 'SibSp', 'Parch', 'Fare', 'p1', 'p2','p3', 'e1', 'e2', 'e3']]
Y_train = data['Survived'].values.reshape(len(data),1)
X_train
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
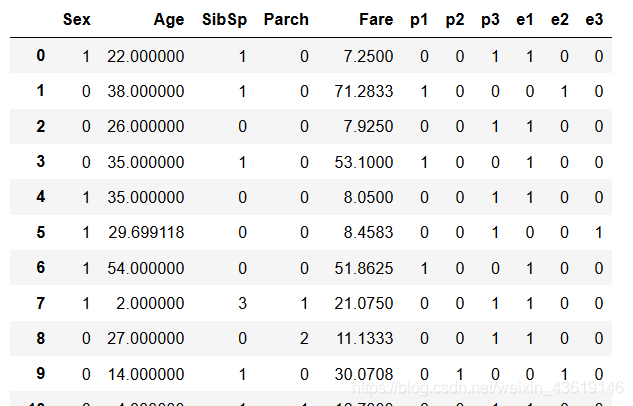
达叔说:对一下维度,这很重要!

2.测试集预处理
data_test = pd.read_csv('test.csv')
data_test = data_test[[ 'Pclass', 'Sex', 'Age', 'SibSp', 'Fare','Parch' ,'Embarked']] #筛选需要的列
data['Age'] = data['Age'].fillna(data['Age'].mean()) #平均值填充
data_test['Sex'] = [1 if x == 'male' else 0 for x in data_test.Sex] #男变为1女变为0
data_test['p1'] = np.array(data_test['Pclass'] == 1).astype(np.int32)#船舱等级变为三列
data_test['p2'] = np.array(data_test['Pclass'] == 2).astype(np.int32)
data_test['p3'] = np.array(data_test['Pclass'] == 3).astype(np.int32)
del data_test['Pclass'] #删除此列
data_test['e1'] = np.array(data_test['Embarked'] == 'S').astype(np.int32)#也变为三列
data_test['e2'] = np.array(data_test['Embarked'] == 'C').astype(np.int32)
data_test['e3'] = np.array(data_test['Embarked'] == 'Q').astype(np.int32)
del data_test['Embarked']
X_test=data_test
X_test
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
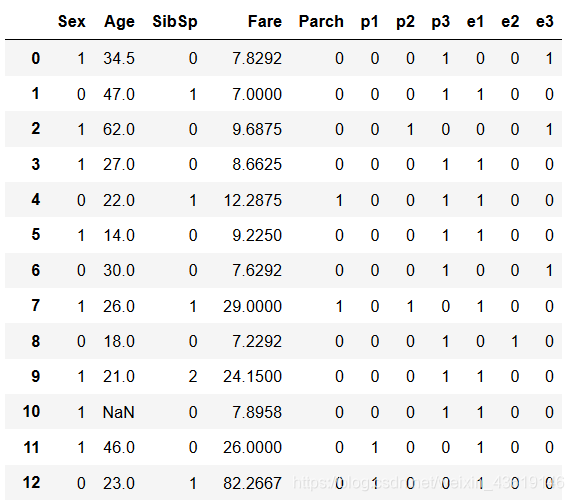
同理,维度:
五.搭建模型
终于到了这一步了,啊哈哈,学了那么多就是等这个呢!!刚开始的话,选一个比较简单的模型,逻辑回归就好,这里我用的是TensorFlow来搭建网络:
import tensorflow as tf
from tensorflow.python.framework import ops
#创建placeholder
X= tf.placeholder(dtype='float',shape=[None,11])
Y = tf.placeholder(dtype='float',shape=[None,1])
#前向传播过程
W = tf.Variable(tf.random_normal([11,1]))
B = tf.Variable(tf.random_normal([1]))
Z = tf.matmul(X,W) + B
pred = tf.cast(tf.sigmoid(Z) > 0.5,tf.float32)#预测结果大于0.5值设为1,否则为0
loss = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(labels=Y,logits=Z))#交叉熵损失函数
train_step = tf.train.GradientDescentOptimizer(0.0003).minimize(loss)#梯度下降法训练
accuracy = tf.reduce_mean(tf.cast(tf.equal(pred,Y),tf.float32))
bed_case=tf.equal(pred,Y)#以后用来看交叉验证集的预测失败例子的
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
六.开始训练
#开始训练
sess = tf.Session() #开启会话
sess.run(tf.global_variables_initializer())#初始化所有变量
loss_train = []
train_acc = []
for i in range(25000):
for n in range(len(Y_train)//100 + 1):
batch_xs = X_train[n*100:n*100+100]
batch_ys = Y_train[n*100:n*100+100]
sess.run(train_step,feed_dict={X: batch_xs,Y: batch_ys})
if i % 5000 ==0:
loss_temp = sess.run(loss,feed_dict={X: batch_xs,Y: batch_ys})
loss_train.append(loss_temp)
train_acc_temp = sess.run(accuracy,feed_dict={X: batch_xs,Y: batch_ys})
train_acc.append(train_acc_temp)
print(loss_temp,train_acc_temp)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17

这就是咱们的代价 和 准确率。百分之八十多还可以。那测试集去试试。
七.测试集预测
#预测测试集
predictions = sess.run(pred,feed_dict={X:X_test})
data_test = pd.read_csv('test.csv')
predictions = predictions.flatten()#二维数组变成一维数组
submission = pd.DataFrame({
"PassengerId": data_test["PassengerId"],
"Survived": predictions
})
submission.to_csv("prdicted.csv", index=False)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
好!这样就保存下来了,但是你要能去Kaggle提交,需要打开文件,另存为CSV UTF-8的形式。
八.提交到Kaggle
打开你的Kaggle,进入这个页面submit
把文档传上去(需要翻墙哦!)然后就可以进行提交了!
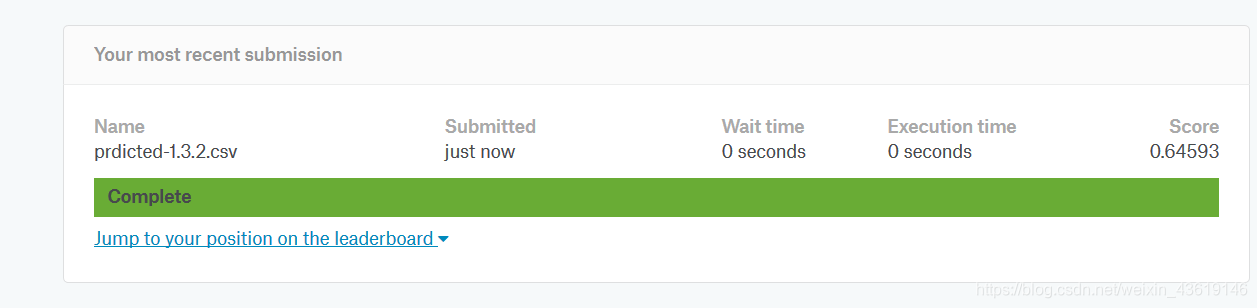 文件名称忘改了 没关系,正确率是0.64593,还可以,毕竟还有很多都特征没有发掘。
文件名称忘改了 没关系,正确率是0.64593,还可以,毕竟还有很多都特征没有发掘。
看看我们的排名:
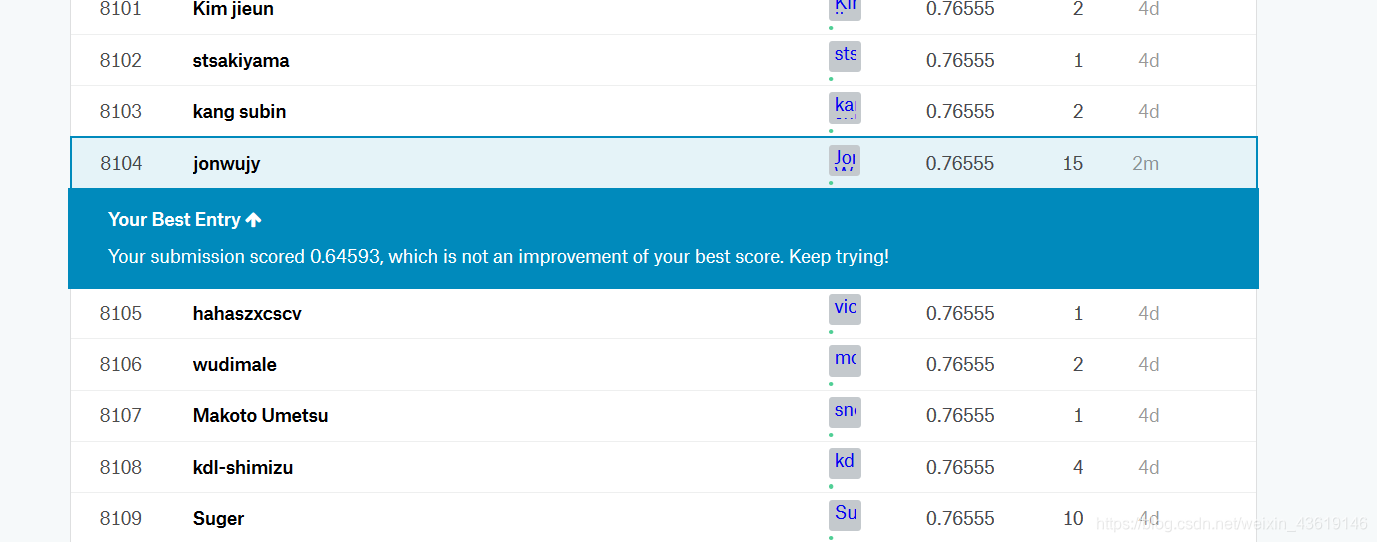 这是我的最好成绩,没办法看当前的排名 不过0.64多 还不错了!
这是我的最好成绩,没办法看当前的排名 不过0.64多 还不错了!
九.总结
这回先写到这吧 ,以上就是一次分析过程,刚刚开始,相信大家应该都有自己的想法没有实现,还想尝试更多,下一篇博客会继续进行,不断地改进模型,改进预处理。这个“指南”仅给和我一样的小白看看,大神们如果我有啥需要改进的地方,请你们不吝赐教,不过黑我就请手下留情!!谢谢。
所属网站分类: 技术文章 > 博客
作者:heer
链接:https://www.pythonheidong.com/blog/article/48963/f4091020f870b9160ec2/
来源:python黑洞网
任何形式的转载都请注明出处,如有侵权 一经发现 必将追究其法律责任
昵称:
评论内容:(最多支持255个字符)
---无人问津也好,技不如人也罢,你都要试着安静下来,去做自己该做的事,而不是让内心的烦躁、焦虑,坏掉你本来就不多的热情和定力